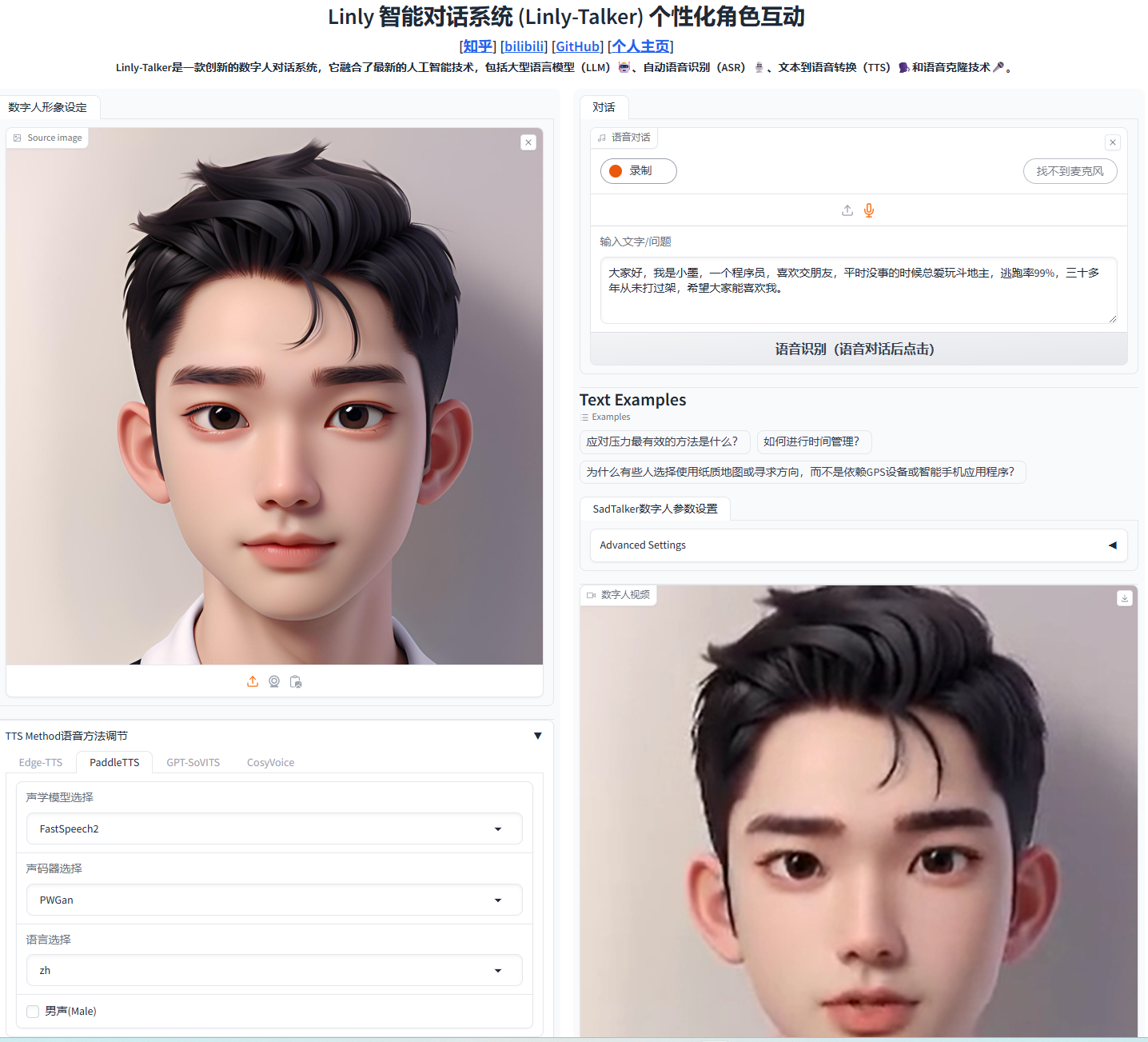
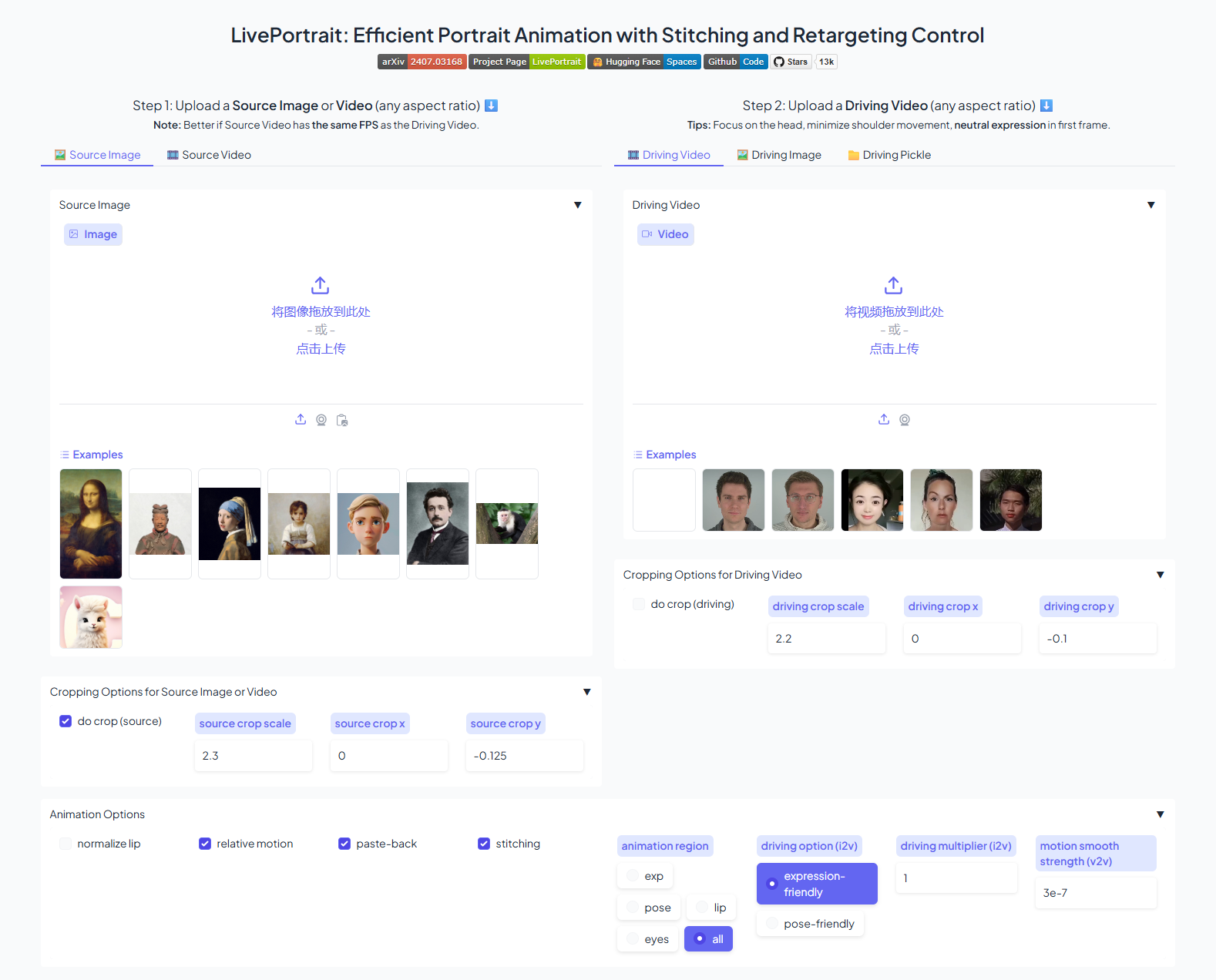
MimicTalk: 几分钟快速训练个性化3D说话头像
Star
Forks
Watch
Issues
MimicTalk是一个基于PyTorch实现的开源项目,能够在几分钟内训练出一个个性化且富有表现力的3D说话头像。该项目构建于先前工作 Real3D-Portrait (ICLR 2024) 之上,Real3D-Portrait 是一个基于NeRF的one-shot说话头像系统,赋予MimicTalk快速训练和高质量的特性。项目提供了演示视频和技术论文,方便用户深入了解其功能和原理。
项目介绍
MimicTalk的核心功能是根据提供的音频和(可选的)风格视频,生成特定人物的说话头像视频。其主要特点包括:
- 快速训练: 得益于Real3D-Portrait的优化,MimicTalk可以在短时间内完成训练,通常几分钟即可训练出一个高质量的模型。
- 个性化: 通过少量目标人物的视频数据,MimicTalk可以生成高度逼真且具有个性化特征的说话头像。
- 表现力: MimicTalk不仅仅是简单的唇形同步,还能模拟人物的面部表情和头部姿态,使生成的头像更具表现力。
- 灵活性: 用户可以提供不同的音频和风格视频,控制生成头像的说话内容、语气和表情。
- 易用性: MimicTalk提供了命令行界面(CLI)和图形用户界面(Gradio WebUI)两种使用方式,方便不同用户群体使用。
MimicTalk的网络架构包含几个关键组件:首先,它利用一个预训练的音频特征提取器提取音频中的语言和情感信息。这些特征被送入一个基于NeRF的生成网络,该网络能够学习从音频特征到3D面部动作的映射。 同时,项目也利用了3DMM BFM 模型来辅助生成更加真实的面部形状和表情。最终,通过渲染技术,将3D面部动作转换为逼真的说话头像视频。
以下是一个简单的流程示意图,展示了MimicTalk的基本工作流程:
优势分析
MimicTalk的优势体现在多个方面:
- 训练速度快: 相比于其他同类项目,MimicTalk的训练速度更快,只需几分钟即可完成训练。这主要归功于其one-shot学习策略和高效的网络架构。
- 生成质量高: MimicTalk生成的说话头像视频具有高度的真实感和逼真度,能够准确地同步唇形、模拟面部表情和头部姿势。
- 可定制性强: 用户可以通过提供不同的音频和风格视频,灵活地控制生成头像的说话内容、语气和表情。
- 易于上手: 项目提供了详细的安装指南和使用教程,以及CLI和WebUI两种使用方式,降低了用户的使用门槛。
使用方法
MimicTalk的使用非常简单,下面介绍两种主要的使用方式:
1. 通过Gradio WebUI使用
Gradio WebUI提供了一个友好的图形界面,方便用户进行交互式操作。
-
安装环境: 首先,请参考安装指南,创建一个名为
mimictalk的Conda环境。 -
下载预训练模型和第三方模型: 从提供的链接下载3DMM BFM模型和预训练的MimicTalk模型,并放置在指定目录。具体结构请参照项目说明。
-
启动 WebUI: 在终端中运行以下命令启动WebUI:
python inference/app_mimictalk.py -
训练和生成: 在Web页面中上传目标人物视频,点击“Training”按钮进行训练。训练完成后,上传驱动音频和(可选的)风格视频,点击“Generate”按钮生成说话头像视频。
2. 通过CLI使用
CLI提供了更大的灵活性和可定制性,适合有一定编程经验的用户。
-
安装环境并下载模型: 同WebUI方式。
-
训练: 使用以下命令训练模型:
python inference/train_mimictalk_on_a_video.py \ --video_id <目标人物视频路径> \ --max_updates <训练步数> \ --work_dir <模型保存路径>例如:
bash python inference/train_mimictalk_on_a_video.py \ --video_id data/raw/videos/German_20s.mp4 \ --max_updates 2000 \ --work_dir checkpoints_mimictalk/German_20s -
生成: 使用以下命令生成说话头像视频:
python inference/mimictalk_infer.py \ --drv_aud <驱动音频路径> \ --drv_style <风格视频路径, 可选> \ --drv_pose <姿势视频路径, 可选> \ --bg_img <背景图片路径, 可选> \ --out_name <输出视频路径, 可选>例如:
bash python inference/mimictalk_infer.py \ --drv_aud data/raw/examples/Obama_5s.wav \ --drv_pose data/raw/examples/German_20s.mp4 \ --drv_style data/raw/examples/German_20s.mp4 \ --bg_img data/raw/examples/bg.png \ --out_name output.mp4 \ --out_mode final
以上命令只是基本使用示例,更详细参数配置请参考项目文档。
社区和贡献
MimicTalk项目在GitHub上获得了较高的关注度,目前Star数量超过1500,这反映了社区对其的兴趣和认可。同时,项目维护者也积极地回应社区的问题和建议,不断地进行更新和改进。通过参与项目贡献,开发者可以进一步了解3D说话头像生成技术,并与来自世界各地的研究者和开发者交流学习。鼓励感兴趣的读者 Star 项目、提交Issue或Pull Request,共同参与项目的发展和完善。
总结
MimicTalk项目提供了一个高效、易用且功能强大的工具,可以快速生成个性化、富有表现力的3D说话头像视频。它在学术研究和实际应用中都具有巨大的潜力,例如:可以用于虚拟主播、数字人、视频会议等领域。未来,项目团队计划进一步优化模型性能,扩展应用场景,并增加更多的功能和特性,例如支持多语言、多人说话等。