AniTalker: 开源 AI 让静态人像开口说话,生成逼真视频
Star
Forks
Watch
Issues
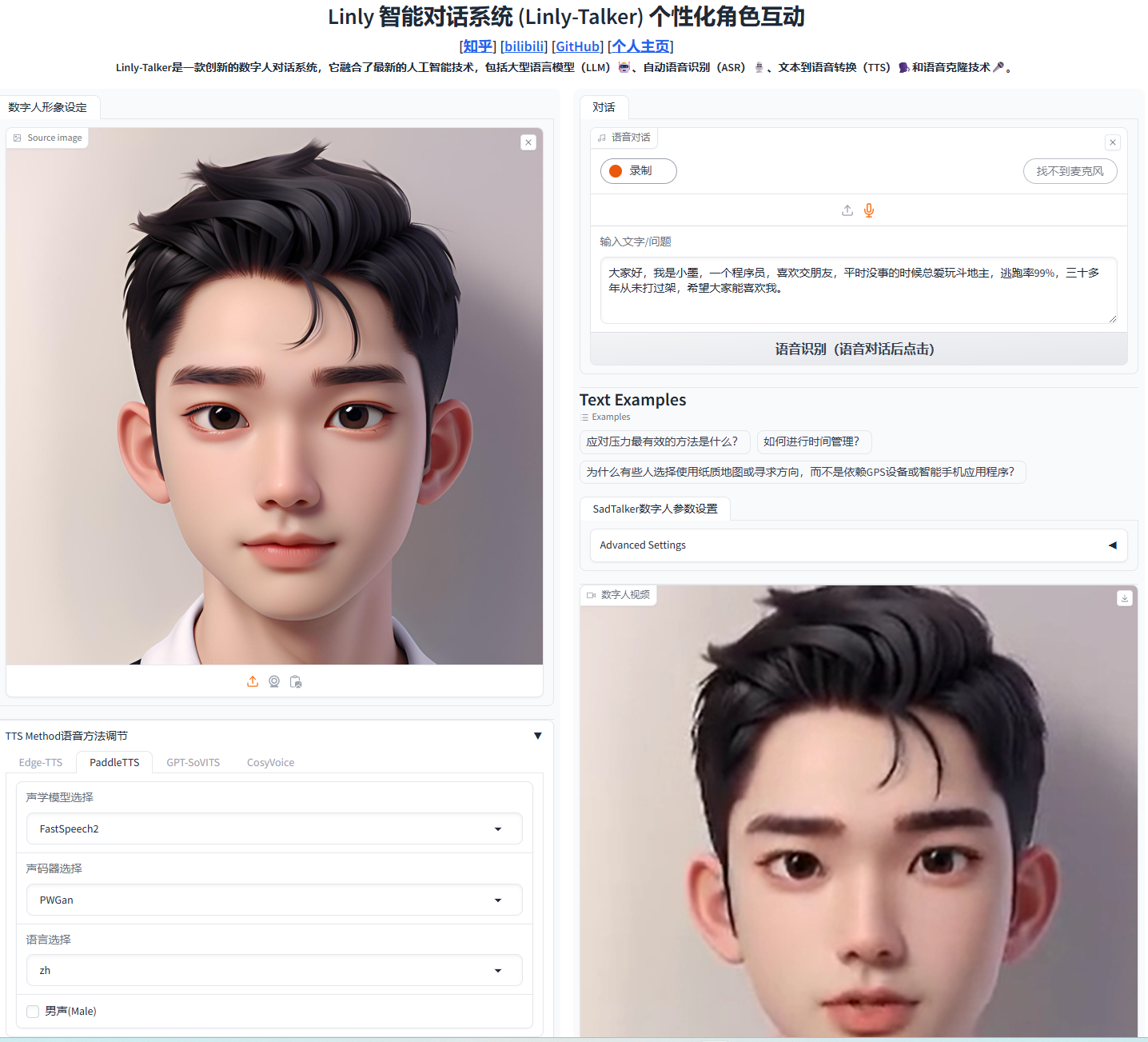
AniTalker 是一个通过身份解耦的面部运动编码来生成生动多样的说话人脸的开源项目。该项目基于深度学习技术,可以将静态人脸图像与语音音频结合,生成逼真自然的说话人脸视频。 不仅如此,AniTalker 还能让用户通过控制头部姿势、位置和缩放等参数来进一步定制生成的视频效果。

项目介绍
AniTalker 项目的核心功能是根据提供的音频驱动静态人像,使其 “开口说话”。项目主要由两个阶段组成:
第一阶段: 专注于训练动作编码器和渲染模块。 这个阶段利用单图像视频数据集,重点学习动作的迁移,为后续生成逼真的人脸动画奠定基础。此阶段完成后,即可使用动作编码器(用于提取与身份无关的动作)和图像渲染器。
第二阶段: 在带有音频的视频数据集上训练模型, 并支持不同的音频特征提取方法,如MFCC和Hubert。第二阶段的模型可以仅通过音频生成动画,也可以结合额外的控制信号(头部姿势、位置、缩放)来生成更具表现力的结果。
项目提供了多个预训练模型,方便用户快速上手体验:
| 阶段 | 模型名称 | 仅音频推理 | 额外控制信号 |
|---|---|---|---|
| 第一阶段 | stage1.ckpt |
- | 动作编码器 & 图像渲染器 |
| 第二阶段 (Hubert) | stage2_audio_only_hubert.ckpt |
是 | - |
| 第二阶段 (Hubert) | stage2_pose_only_hubert.ckpt |
是 | 头部姿势 |
| 第二阶段 (Hubert) | stage2_full_control_hubert.ckpt |
是 | 头部姿势/位置/缩放 |
| 第二阶段 (MFCC) | stage2_pose_only_mfcc.ckpt |
是 | 头部姿势 |
| 第二阶段 (MFCC) | stage2_full_control_mfcc.ckpt |
是 | 头部姿势/位置/缩放 |
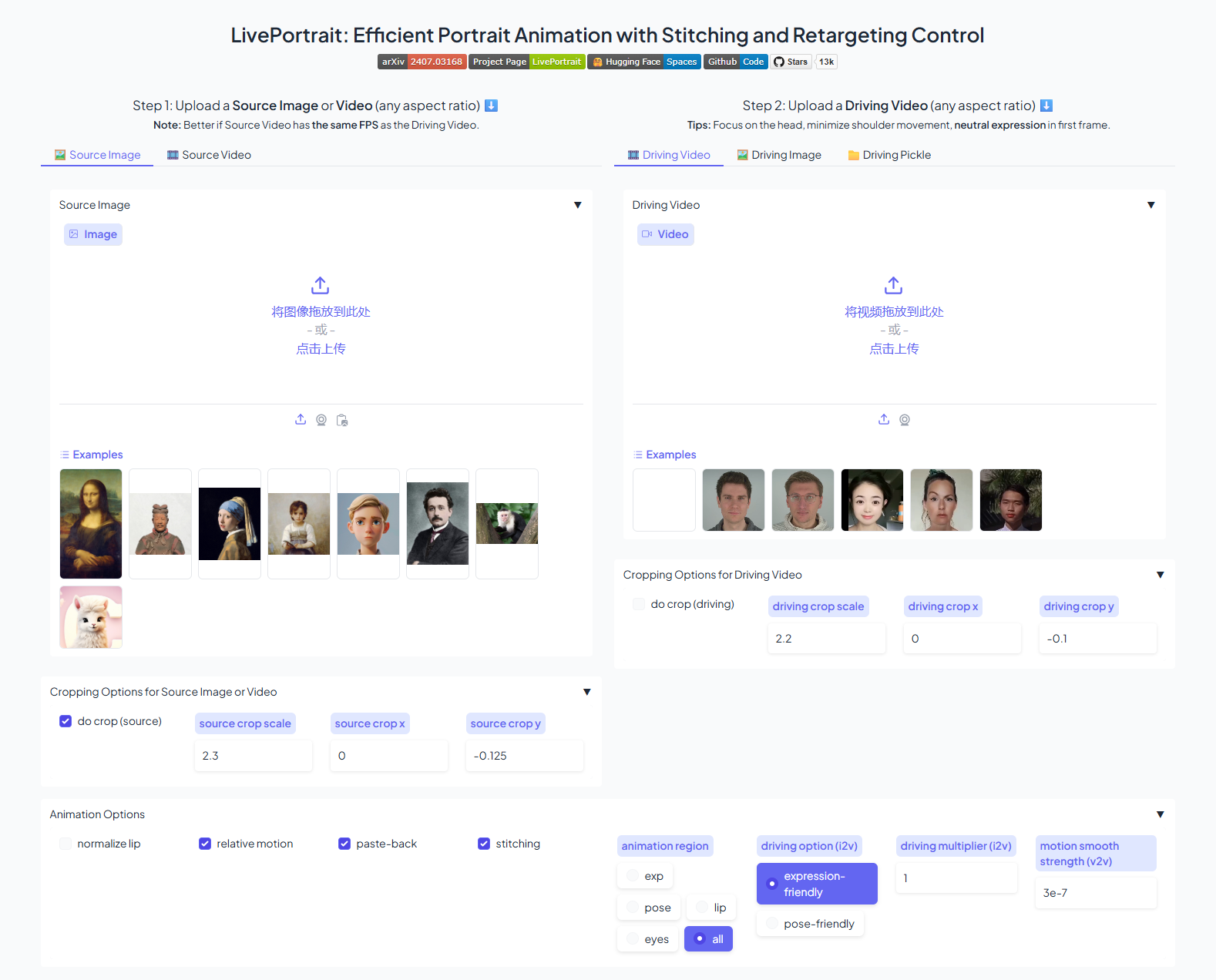
项目还提供了Web UI 和 Google Colab 演示,方便用户快速体验和测试:
- Web UI: 提供了图形化的用户界面,用户可以通过简单的操作上传图片和音频,并调整参数生成动画。
- Google Colab 演示: 用户可以直接在Colab环境中运行示例代码,无需本地安装任何依赖。
以下是一个简单的示例,展示如何使用 stage2_audio_only_hubert.ckpt 模型生成蒙娜丽莎说话的视频:
python ./code/demo.py \
--infer_type 'hubert_audio_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_audio_only_hubert.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/monalisa.wav' \
--test_hubert_path 'test_demos/audios_hubert/monalisa.npy' \
--result_path 'outputs/monalisa_hubert/'
只需提供目标图像 ( --test_image_path) 和驱动音频 ( --test_audio_path),模型即可自动生成相应的说话人脸视频。
优势分析
AniTalker 项目具有以下优势:
- 生成效果逼真: 采用先进的深度学习模型,生成的说话人脸视频具有高度的逼真度和自然度,唇形同步准确,表情生动。
- 灵活性强: 支持多种音频特征提取方法,并提供丰富的控制参数,用户可以根据需求灵活调整,生成不同风格和效果的动画。
- 易用性高: 提供了详细的安装和使用教程,以及Web UI 和 Google Colab 演示,用户可以快速上手体验。
- 社区活跃: 项目在 GitHub 上拥有较高的 Star 数量,并且有持续的贡献者提交代码和改进文档,社区活跃度高,问题反馈和解决速度快。
- 模型多样: 提供了多种预训练模型,满足不同用户的需求。
使用方法
1. 环境安装
首先创建一个 conda 环境,并安装必要的依赖包:
conda create -n anitalker python==3.9.0
conda activate anitalker
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip install -r requirements.txt
此外, 如果需要使用人脸超分辨率功能, 则需要安装额外依赖:
pip install facexlib
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install gfpgan
2. 模型下载
从 Hugging Face Hub 下载预训练模型 checkpoint 文件,并将其放置在 ckpts 文件夹中。国内用户可以从百度网盘下载。
3. 运行 Demo
可以使用提供的 demo.py 脚本运行示例, 例如, 使用stage2_audio_only_hubert.ckpt 模型运行:
python ./code/demo.py \
--infer_type 'hubert_audio_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_audio_only_hubert.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/monalisa.wav' \
--test_hubert_path 'test_demos/audios_hubert/monalisa.npy' \
--result_path 'outputs/monalisa_hubert/'
生成结果会保存在 --result_path 指定的路径下。
4. 详细参数配置
项目的参数配置说明可以在 参数配置 中找到。
社区和贡献
AniTalker 在 GitHub 上获得了很高的关注度, Star 数量不断增长。 社区中有大量的用户提交 issue, 开发者也积极回应并修复问题。项目还吸引了许多贡献者提交代码, 共同完善项目功能和文档。活跃的社区氛围保证了项目的持续发展和迭代。开发者鼓励更多人参与到项目贡献中,包括提交代码、修复 Bug、改进文档、分享使用案例等。
总结
AniTalker 项目为生成逼真说话人脸动画提供了一种强大且易用的工具。它不仅具有高质量的生成效果,还提供了丰富的可定制选项。 该项目活跃的社区也确保了其持续的维护和更新。 未来, 开发者计划添加自动校准第一帧的功能,并探索更广泛的应用场景,例如虚拟人直播、数字内容创作等。