返回
Crawl4AI: 免费开源异步爬虫,赋能LLM与AI应用
Star
Forks
Watch
Issues
Crawl4AI 是一个免费、开源且功能强大的异步网络爬虫和数据提取工具,专为大型语言模型 (LLM) 和 AI 应用设计。它提供高速、灵活且易于使用的解决方案,用于从网站提取信息并将其转换为结构化数据,从而简化了 AI 应用的数据获取流程。
项目介绍
Crawl4AI 通过异步网络爬取和数据提取技术,帮助用户快速、高效地从网站收集信息。它支持多种数据提取策略,包括 CSS 选择器、自定义 JavaScript 代码执行和基于 LLM 的提取,可以满足各种数据采集需求。此外,Crawl4AI 还支持代理、会话管理和缓存控制等功能,可以应对复杂的网络环境和动态网页内容。
优势分析
Crawl4AI 具有以下显著优势:
- 免费开源: Crawl4AI 完全免费且开源,用户可以自由使用、修改和分发。
- 高性能: Crawl4AI 采用异步架构,可以同时处理多个网页请求,显著提高爬取效率。
- LLM 友好: Crawl4AI 支持多种输出格式,包括 JSON、Markdown 和清洗后的 HTML,方便 LLM 直接使用。
- 灵活易用: Crawl4AI 提供简单易用的 API,用户可以轻松上手,并根据需求自定义爬取策略。
- 功能丰富: Crawl4AI 支持多种功能,包括 JavaScript 代码执行、CSS 选择器、代理、会话管理等,可以应对各种复杂的爬取场景。
使用方法
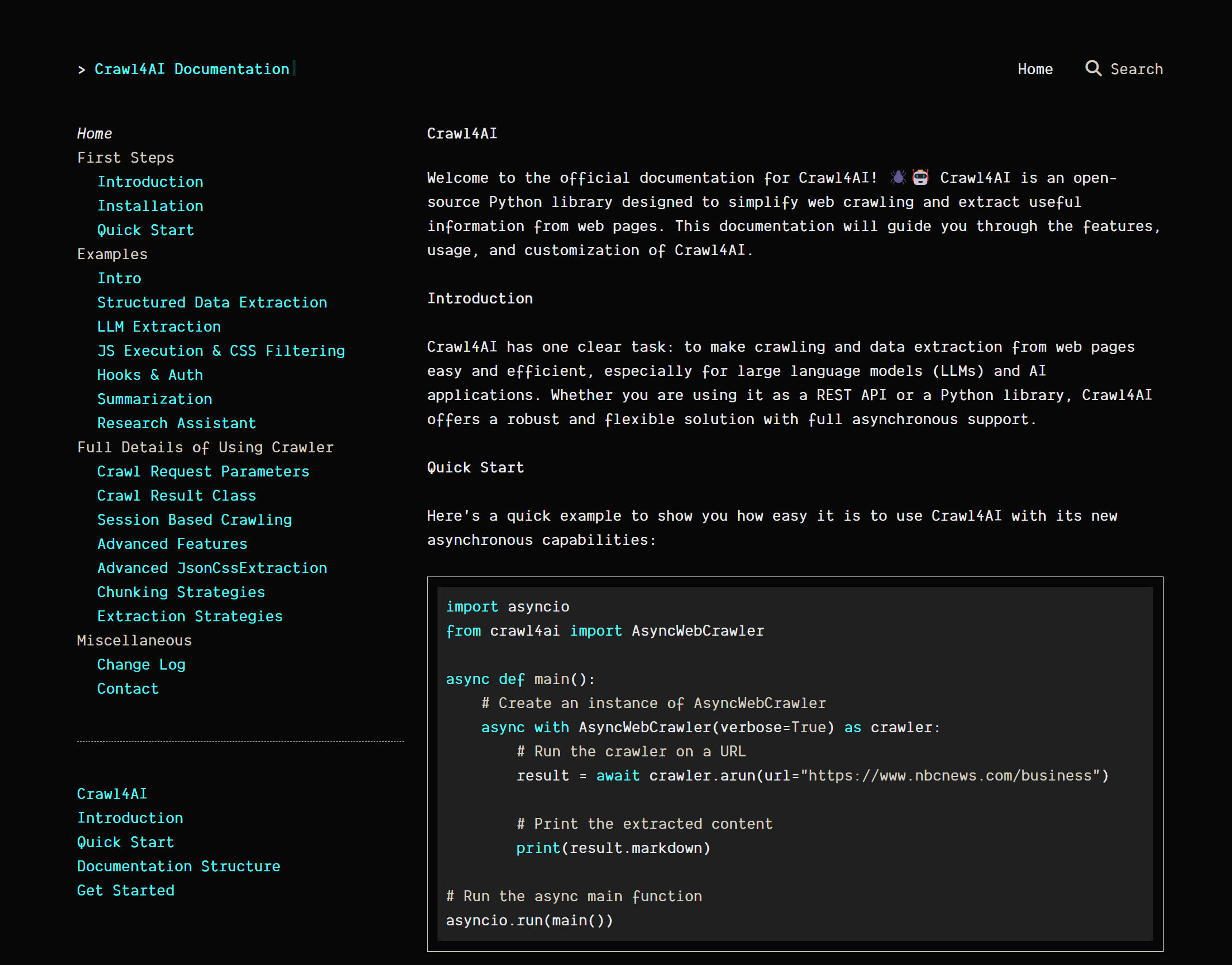
Crawl4AI 的使用方法非常简单,以下是一个基本的示例:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.example.com")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
用户可以通过 AsyncWebCrawler 类创建一个爬虫实例,并使用 arun 方法发起爬取请求。arun 方法接受一个 URL 参数,并返回一个 CrawlResult 对象,其中包含爬取结果,例如网页内容、提取的数据等。
对比分析
与其他网络爬虫工具相比,例如 Scrapy 和 Beautiful Soup,Crawl4AI 具有以下优势:
- 异步爬取: Crawl4AI 采用异步架构,可以显著提高爬取效率,而 Scrapy 和 Beautiful Soup 则主要采用同步爬取方式。
- LLM 支持: Crawl4AI 专为 LLM 设计,支持多种 LLM 友好的输出格式,而 Scrapy 和 Beautiful Soup 则需要用户自行处理数据格式转换。
- 易用性: Crawl4AI 提供简单易用的 API,用户可以轻松上手,而 Scrapy 和 Beautiful Soup 则需要用户编写较多的代码。
社区和贡献
Crawl4AI 是一个活跃的开源项目,拥有不断增长的社区。用户可以通过 GitHub 提交问题、贡献代码或参与讨论。
总结
Crawl4AI 是一个功能强大的异步网络爬虫和数据提取工具,它为 LLM 和 AI 应用提供了高效、灵活的数据获取方案。Crawl4AI 具有免费开源、高性能、易用性强等优势,并且拥有活跃的社区支持。未来,Crawl4AI 将持续改进功能,例如支持更多的 LLM 模型、提供更强大的数据提取策略等,以满足用户不断变化的需求。